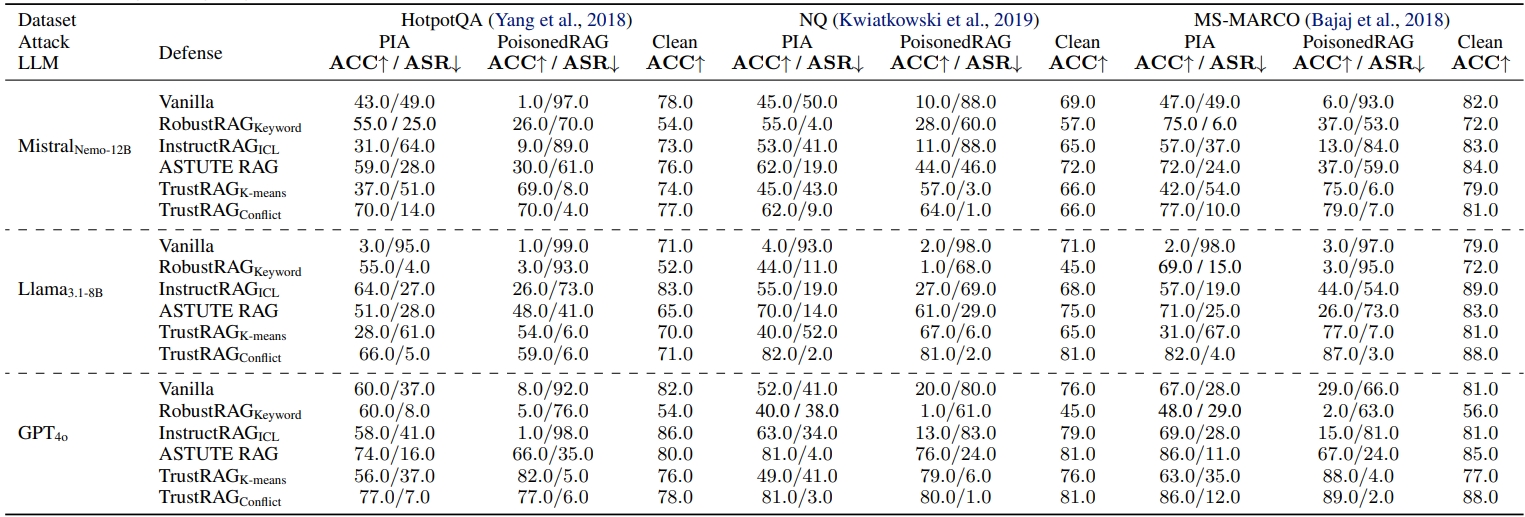
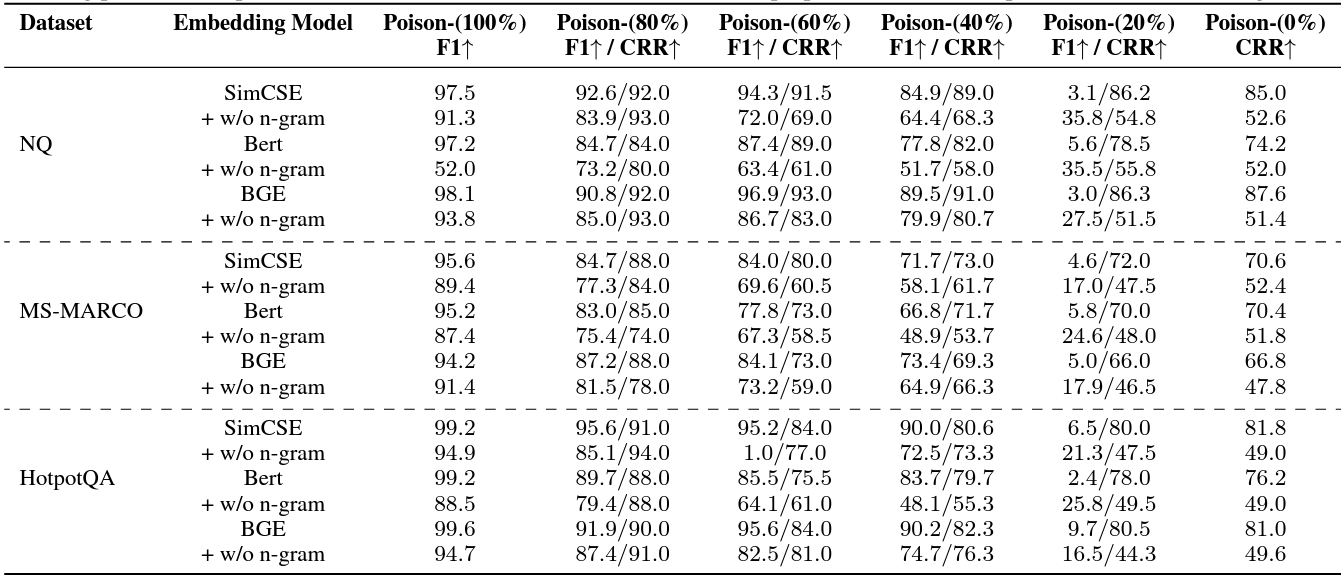
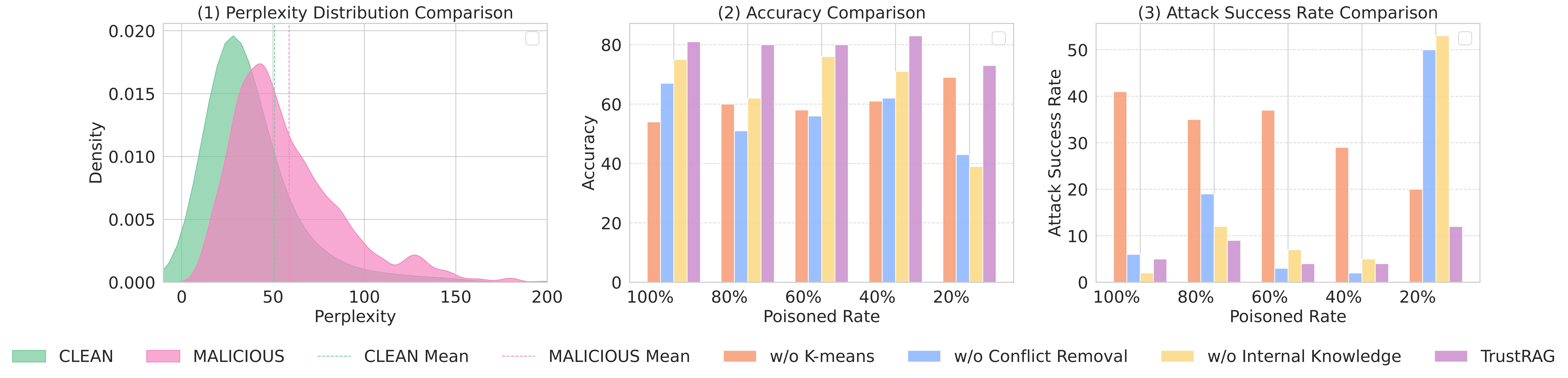
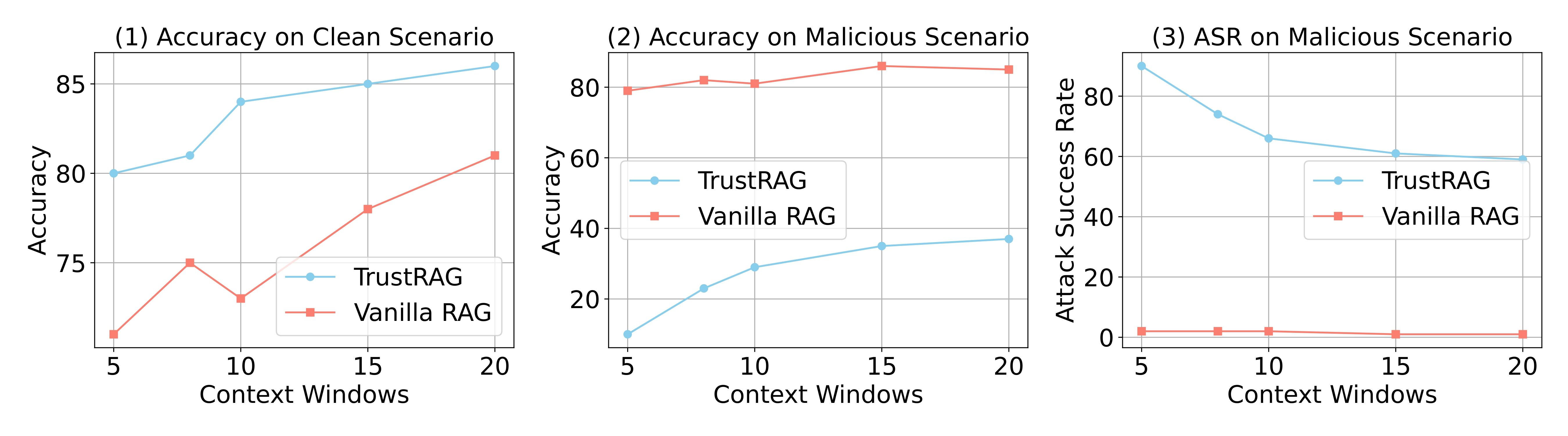
Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by integrating external knowledge sources, enabling more accurate and contextually relevant responses tailored to user queries. However, these systems remain vulnerable to corpus poisoning attacks that can significantly degrade LLM performance through the injection of malicious content. To address these challenges, we propose TrustRAG, a robust framework that systematically filters compromised and irrelevant content before it reaches the language model. Our approach implements a two-stage defense mechanism: first, it employs K-means clustering to identify potential attack patterns in retrieved documents based on their semantic embeddings, effectively isolating suspicious content. Second, it leverages cosine similarity and ROUGE metrics to detect malicious documents while resolving discrepancies between the model's internal knowledge and external information through a self-assessment process. TrustRAG functions as a plug-and-play, training-free module that integrates seamlessly with any language model, whether open or closed-source, maintaining high contextual relevance while strengthening defenses against attacks. Through extensive experimental validation, we demonstrate that TrustRAG delivers substantial improvements in retrieval accuracy, efficiency, and attack resistance compared to existing approaches across multiple model architectures and datasets. We have made TrustRAG available as open-source software at https://github.com/HuichiZhou/TrustRAG.